
在上一期中,我们从自然语言处理的底层逻辑出发,概述了行业发展范式及算法演进,进而将目光聚焦在了目前市场上的主导类产品——以Transformer算法为基础的ChatGPT及Deepseek系列大参数模型上,本期我们将就大模型的软件及算法开展初步的技术解析。
一、大参数模型的特征定义
Transformer 架构是大模型革命的 “骨架”,其核心是注意力机制。这种技术就像人类阅读时会自动划重点一样,能让模型自动识别文本中的关键信息,并基于此展开后续基于概率预测的文本内容自生成。以 Google 的 BERT 模型为例,通过双向注意力机制,它在理解 “银行” 这个词时,能够自动区分其是指金融机构还是河岸边。
但传统的Transformer模型在实际使用中可以明确地感受到,如在长文本或者复杂场景下,概率预测的算法失灵。直到2020年基于Scaling Laws的GPT3模型的发布,AI语言处理算法才初步达到了可用的状态。Scaling Laws是一个基于经验而非理论的模型,即,通过算力、数据及参数的指数堆叠,以参数量变诱发智能质变。
从实际情况来看,2018 年诞生的 GPT - 1 仅有 1.17亿参数,到 2023 年,GPT - 4 的参数已突破 1.8 万亿,在短短 5 年内增长了 1.6 万倍。随着参数量的上涨,一个直观的对比是,GPT - 3(1750 亿参数)仅仅能够完成基础的文本生成任务(需人工的大量干预及提示词工程,同时模型Agent的智能程度不高于中学教育水平),而 GPT - 4(1.8 万亿参数)则可以如一个行业专家般解析法律条款中的隐藏逻辑。这种能力的提升,类似于孩童从单纯背诵唐诗,到能够理解诗歌意境的认知跨越。
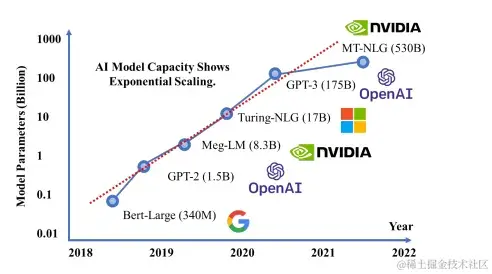
模型参数增长曲线,来源,稀土掘金技术社区
二、基于Scaling Laws的算力 / 数据 / 算法协同创新
斯坦福大学等机构的研究表明,当模型参数量(Parameters)、训练数据量(Data)和计算量(Compute)按比例同步扩展时(即满足"Scaling Law"),模型性能会通过增强的泛化能力和高阶模式识别实现指数级提升。
GPT-4的进化路径完美验证了该理论:其参数量较前代增长10倍以上,训练数据扩容20倍,算力投入提升68倍,这种三维协同缩放最终催生了语言智能的质变飞跃。
然而,三者的平衡至关重要,就好比建造摩天大楼,既需要坚实的地基(数据),也需要优质的建材(算力),更需要精密的设计(算法),过度侧重单一因素可能导致边际效益递减或资源浪费。
(1)硬件与算力新基建:
训练GPT-4所需的计算资源规模远超GPT-3,其训练过程需同时调用2.5万块A100显卡,而GPT-3仅需约1500块。单次训练耗电量高达5000万度,相当于5000户家庭一年的用电总量。根据2023年测算数据,该模型处理每个用户请求的平均能耗为2.9-8.9度电,年运营总耗电量更是接近2亿度。
这一计算需求带来了巨大的产业挑战:一方面,模型训练需依赖海量先进芯片产能,并涉及超十亿元级别的一次性资金投入;另一方面,算力的指数级增长也对计算服务器、通信带宽、散热系统及电力供应等基础设施提出了前所未有的严苛要求。
(2)语料数据来源:
作为大语言模型的核心训练基材,GPT系列依赖高质量语料构建语言认知体系。OpenAI当前采用的训练语料规模已突破5万亿token(约合数万亿单词量级),这一数据规模相当于将人类现存所有文字著作数字化后反复精读数万次。从认知科学视角来看,大模型通过海量语料内化形成的语言表征系统,本质上是将人类文明数千年的知识沉淀转化为可计算、可泛化的智能范式。
(3)算法创新:
随着大模型参数量呈指数级攀升,其对算力、语料及硬件资源的需求呈现爆发式增长。在此背景下,算法优化正逐渐演变为构筑产品核心竞争力的关键突破口。传统模式下,在计算资源充沛的场景中,"力大砖飞"式算法即可满足基准质量输出;而面对资源受限环境,通过算法精细化改进与创新性机制引入,往往能为大模型训练带来数倍效率增益。以DeepSeek开源的混合精度训练技术为例,该方案成功实现3倍计算效率跃升,显著降低了训练与运营成本。
算力基建、语料储备与算法创新的三重协同效应,正推动AI生产力实现跨越式发展。对比数据颇具说服力:2020年训练中等规模模型需耗时约3个月,而得益于技术进步,2024年同等任务的训练周期已压缩至3周左右。这种指数级的速度提升,标志着大模型研发模式正在发生根本性变革。
大模型的投入产出比呈现出明显的边际效益递减规律,遵循"指数级投入、线性增长"的基本特征。以GPT系列为例,当参数规模从10亿增至1000亿时,训练成本暴涨100倍却仅获得80%的性能提升;而当参数继续扩大到1万亿规模,成本再增10倍的情况下性能增益已骤降至15%。这种收益急剧衰减的现象正在推动行业探索更高效的替代方案,例如谷歌的PaLM模型通过优化数据质量而非数量,仅用三分之一的数据量就实现了更优效果,而混合专家系统等新兴架构也在尝试重构大模型的成本效益曲线。
面对这种"规模不经济"的困境,AI行业正在经历从盲目扩张到精细化运作的战略转型。最新的行业情况显示,头部实验室将大量的研发资源投入到训练效率优化领域,而非单纯的参数堆砌。这种转变不仅印证了"更大未必更好"的行业新认知,更预示着大模型发展正在进入一个以创新架构和智能训练为核心的新阶段。
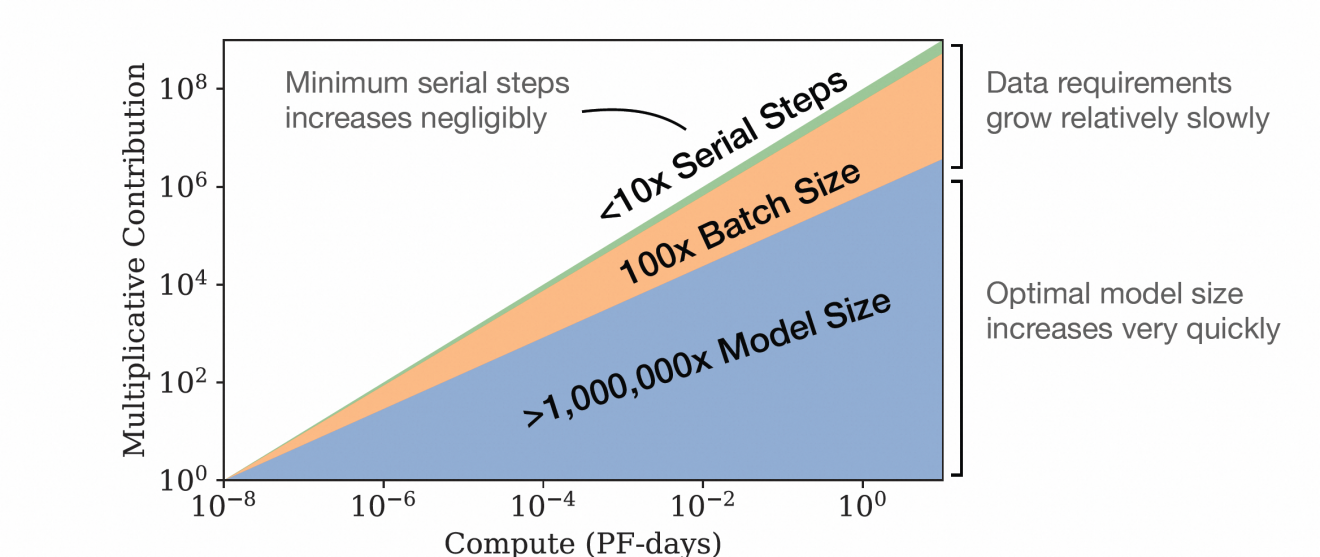
Scaling laws缩放法则,来源,OpenAI论文《Scaling Laws for Neural Language Models》
三、大模型的算法黑箱初探
大模型的核心能力源于数据、算力与参数在算法框架下的协同作用,这一机制使其具备了强大的自然语言处理能力。
然而当前研究重点主要集中在数据到参数的训练算法上,对于参数量突破临界值后模型为何能涌现智能这一关键问题,学界仍缺乏系统性理论解释。这也正是大模型常被称为"算法黑箱"的根本原因。本文将分两部分探讨大模型算法:首先梳理算法发展历程,随后详细解析Transformer的基础原理。
(1)大模型算法的发展概述
早期自然语言处理以卷积神经网络(CNN)为机器学习的研究主流方向,CNN的设计灵感来源于视觉皮层处理信息的方式,就像人眼先识别边缘再组合形状一样,卷积神经网络通过层层抽象提取特征,即由底层识别线条,中层组合成部件,高层理解完整图像。
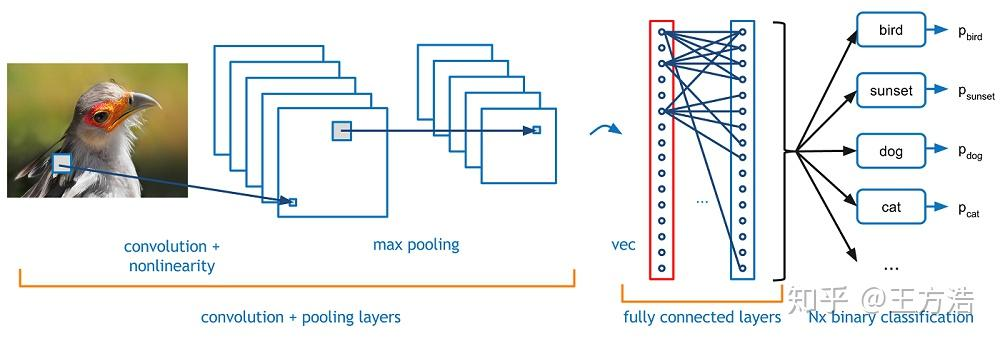
卷积神经网络(CNN)图示,来源,知乎用户-王方浩
CNN擅长通过局部卷积提取图像等网格数据的特征,但面对自然语言处理(NLP)等长序列任务时,其局部感受难以捕捉长距离关联。后续虽然经过了RNN(循环神经网络)\LSTM(细胞网络)\Seq2Seq(序列模型)的迭代,其性能仍无法满足长文本的处理要求。
直到2017年Attention算法机制的引入,大模型算法才终于突破长距离文本的计算局限。并在不久后,Transformer算法在Attention的基础上,升级了其自注意力机制(Self-Attention),最终以长文本处理能力及高效运算为特点,成为了NLP和跨领域任务的主流架构。
Transformer算法在机器翻译中,可以同时计算句子中所有词语的关联性,达到显著提升语义理解的准确性的效果。此外,Transformer的并行化训练也大幅提升了模型效率,解决了过往算法的序列依赖瓶颈。
随着GPT、BERT等模型的成功,Transformer不仅在NLP领域占据主导,还扩展至图像生成、蛋白质结构预测等跨模态任务。当前,研究者进一步探索CNN与Transformer的融合架构(如CTrans),结合局部特征提取与全局建模能力,推动AI模型在多领域的综合性能提升。

图片截取自厦门大学《大模型概念、技术与应用实践》
(2)Transformer算法的基础原理
Transformer的核心可以理解为一种“智能关联分配器”。它的核心是自注意力机制,就像给每个词装了一双“能看全局的眼睛”。举个例子,当模型处理“猫坐在垫子上”这句话时,它会为每个词(如“猫”“垫子”)计算与其他所有词的关联强度/概率(即注意力分数)。比如对“猫”而言需要计算它和“坐”及“垫子”的关联概率谁更高,从而分配权重。
算法的具体实现分为三步:
1、生成Q、K、V:每个词被转换成三种向量——查询(Query)、键(Key)、值(Value),类似于“提问”“关键词”“答案”的角色。
2、计算注意力分数:用Q和K的点积衡量词间相关性(如“猫”和“垫子”的关联),再通过Softmax归一化为概率分布密度,决定每个词的概率关联权重。
3、加权融合:用权重对V进行加权求和,生成新的词表示(任务输出结果)。例如,这句话的新表示,如翻译文本,将会包含“猫”“坐”和“垫子”的概率分布密度权重,并以参数进行最优化求和。
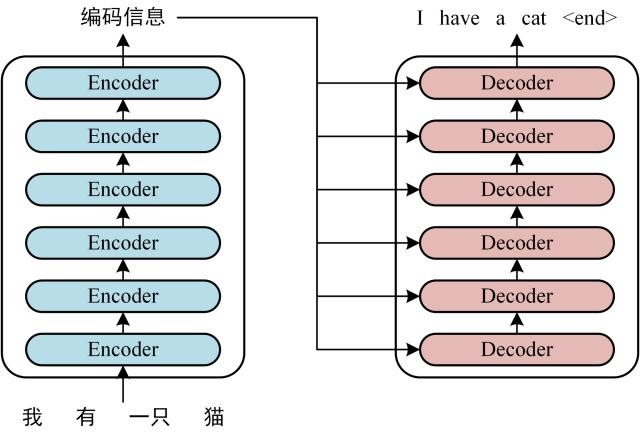
Transformer编码解码图示,来源,CSDN-沧海明月
为提高灵活性,Transformer还引入多头注意力,让模型同时关注不同角度的关联(如语法、语义),类似于多组不同语言领域的专家分别分析后再综合结果,形成多组角度的横向密度分布。
此外,算法还将通过位置编码为序列添加顺序信息,避免模型将“猫追狗”和“狗追猫”视为相同。最终,编码器-解码器结构通过多层堆叠,逐步提炼输入与输出的复杂关系,完成翻译、生成等任务。
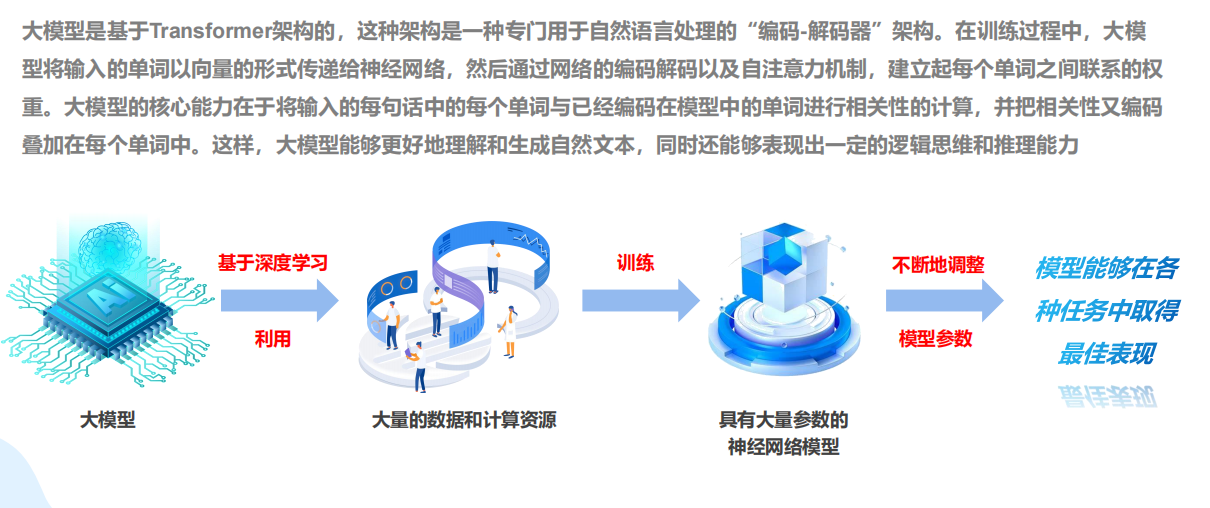
图片截取自厦门大学《大模型概念、技术与应用实践》
四、大模型算法幻觉的底层逻辑
大模型的核心能力建立在海量文本的统计规律学习之上,通过分析数万亿级别的语料数据,模型能够精准掌握词语之间的关联概率。例如,在训练数据中,"天空"与"蓝色"的共现概率显著高于"天空"与"香蕉"的组合。这种基于概率的预测机制虽然能够生成流畅自然的语句,但其本质仍是统计学层面的"最优解"计算,而非真正的语义理解。
这种基于统计的学习方式也带来了明显的局限性。当面对训练数据中未充分覆盖的场景时,模型会依据错误的关联概率生成看似合理实则失真的内容,就像人类会无意识地"脑补"缺失信息一样。研究发现,随着模型参数规模的扩大,这种"幻觉"现象反而可能加剧,因为更复杂的关联网络会赋予更多词语组合以看似合理的高概率值。例如,模型可能会错误地输出"马斯克发明了交流电"这样的陈述,仅仅因为在训练数据中"马斯克"与"科技发明"之间存在较强的统计关联。
为了修正这些系统性偏差,研究人员采用了基于标注数据的"定向校准"方法。这种方法类似于教师批改学生作业,通过大量的人工标注(如将"太阳从西边升起"明确标记为错误)来调整模型的概率权重分布。然而实践表明,即便投入大量人工监督进行微调,大模型在关键领域的错误率最多只能降低60%左右。这不仅印证了模型"黑箱"特性的顽固性,也凸显了人工智能训练过程中面临的根本性挑战:在可解释性缺失的情况下,通过人为干预来提升模型准确性的边际成本正在急剧上升。
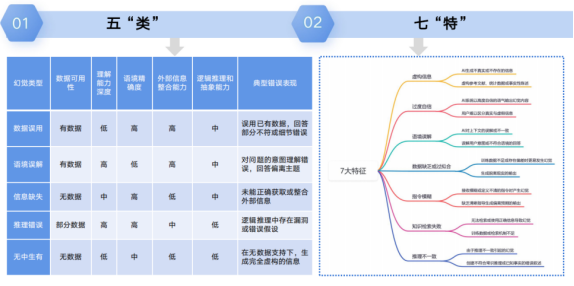
图片截取自清华大学《DeepSeek:从入门到精通》
五、参数临界点后的智能质变现象
基于Transformer架构的大模型本质上是概率科学与人类智慧融合的结晶。回溯至2020年,当千亿参数的GPT-3横空出世时,尽管其在多个领域实现了革命性突破,但由于模型智能水平的局限,输出结果往往需要大量人工干预。这一现状甚至催生了一门新兴学科——针对GPT系统的提示词工程(Prompt Engineering)。当时的用户为了获得稳定可靠的输出,不得不设计从角色定位到输出语法的整套复杂提示词体系。
然而时隔四年,以Deepseek为代表的当代大模型已实现质的飞跃。如今用户仅需输入一段简洁明确的指令,即可获得令人满意的输出结果。这种显著的性能提升,学界通常称之为"规模效应引发的智能涌现"现象,其主要表现为以下几个方面:
(1)上下文学习(ICL)机制
当模型参数突破千亿级时,模型突然获得了“举一反三” 的能力。例如:
给出3 个中译英的示例,模型就能自动翻译第 4 个句子;
展示5 道数学题的解法,模型可以解出第 6 道全新的题目。
这种被称为"上下文学习"(In-context Learning)的能力,恰如教育领域所追求的"触类旁通"效果——通过有限样例掌握通用解题方法。据2022年OpenAI发布的GPT-3技术报告显示,该能力在参数规模达到620亿时初现端倪,至1750亿参数时趋于成熟稳定。
(2)思维链(CoT)推理能力跃迁
同时,随着模型参数规模的扩张,大语言模型展现出类人的分步推理能力。以典型数学问题为例:
问题:小明有5个苹果,吃掉2个,妈妈又给他3个,现在有几个?
解答过程:
1\. 初始数量:5个
2\. 吃掉后剩余:5 - 2 = 3个
3\. 增加后总数:3 + 3 = 6个
答案:6个
这种分步推理能力在参数达到百亿级时出现质变,基于标准化的模型能力评估体系,在数学推理任务中,配备CoT机制的千亿参数模型相较十亿级基线模型可实现超过40%的准确率提升,这验证了模型规模与复杂推理能力间的非线性增长关系。
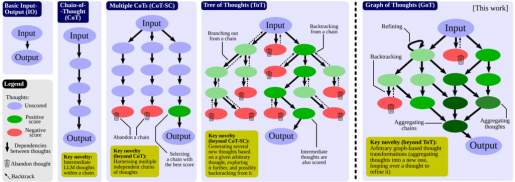
图片截取自《Graph of Thoughts: Solving Elaborate Problems with Large Language Models》
(3)多模态对齐的相变现象
当模型规模突破临界点时,会突然展现出跨模态的理解能力,如:
视觉-语言模态:输入《蒙娜丽莎》画像时,模型不仅能识别绘画对象,更能生成"似笑非笑的微妙表情透露出文艺复兴时期的神秘美学"等蕴含艺术理解的描述;
文本-视频模态:给定菜谱文本输入,模型可自动分解烹饪步骤,并生成包含食材处理、火候控制等关键帧的短视频脚本;
听觉-语言模态:聆听《月光奏鸣曲》音频时,模型能创作出"银色音符在寂静中流淌,如同月光穿透云层的裂隙"等意境高度契合的诗歌。
这种能力的突现类似于冰融化成水的相变过程。根据现有的数据计算,当大模型的图文联合训练数据达到50 亿时,模型开始自主建立跨模态关联,到 200 亿时形成稳定多模态对齐能力。

图片截取自厦门大学《大模型概念、技术与应用实践》
六、大模型的前沿算法应用成果
(1)混合专家系统MoE 的动态路由机制
在传统大模型架构中,系统通常采用单一密集网络结构,即通过统一的模型处理所有任务类型。相比之下,基于混合专家(Mixture of Experts, MoE)的架构实现了处理效率的突破:其内部构建了多个专业化子网络模型,每个子模型作为特定领域的"专家模块"(如语法解析、语义理解等),并通过可训练的门控网络(Gating Network)实现动态的任务分配。
例如,MoE架构模型在处理“高能物理” 相关文本时,会自动激活物理知识专家,而在诗歌生成任务中则调用文字逻辑专家。这种动态调度使得万亿参数模型的实际计算量接近小规模密集模型,而非线性增长(减少50%~85%的计算量)。
同时,若从系统资源角度观察,传统密集模型类似于持续满负荷运转的工业厂房,无论任务复杂度如何都需激活全部计算单元;而MoE架构则更接近智能能源管理系统,能够根据任务需求精确调配计算资源——处理简单查询时仅需激活3%~5%的神经元,面对复杂任务时则按需扩展至20%~30%。这种设计使训练能耗降低了 至少40%,同时,同规模硬件的推理速度提升了 2 倍以上。
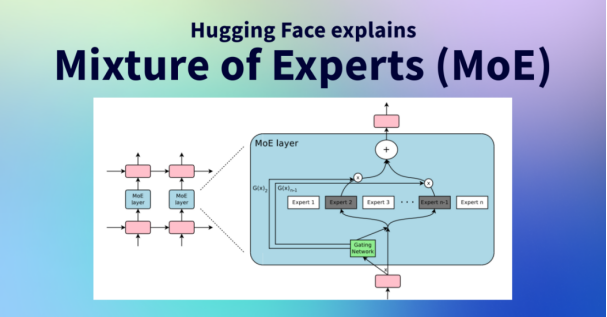
混合专家模式MoE,来源,Hugging Face Web
(2)专家分组通信延迟优化技术
在引入混合专家(MoE)架构后,专家模块间的通信延迟一度成为训练效率的主要瓶颈,在万卡集群中占比高达40%。这主要是由于专家间的指令调度存在严重的通信拥塞,导致大量时间浪费在数据传输上。通过“专家就近分组”策略,将协作紧密的专家优先部署在同一服务器组,并结合“梯度压缩”技术,仅传输关键梯度而非完整参数,通信开销成功降至15%以下。这一优化大幅提升了专家系统的协作效率,相当于将原本低效的“跨国飞行会议”转变为高效的“线上短会”,使模型训练的整体吞吐量得到显著提升。
(3)3D 并行训练技术创新
传统大模型在训练中,会遇到训练设备由于训练量的波动,导致频繁运算加减速而损失效率的问题。而3D并行技术是指通过整合数据并行、张量并行和流水线并行三个维度的优化,提升千亿级以上参数模型的训练效率的方法,直观而言:
数据并行可以理解为把《红楼梦》拆分成100 份,分给 100 个读书小组同时阅读;模型(张量)并行可以类比将大脑类比为分成视觉区、语言区等分别进行训练,最后组合成完整的智能;流水线并行如同工厂的流水线,每个环节专注于特定的计算任务。
通过三维并行技术,训练万亿参数模型的时间可以从理论上的30 年压缩为实际上的 3 个月以内。
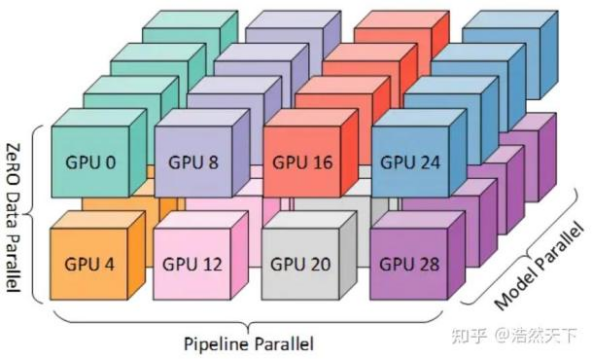
3D并行训练,来源,知乎用户-浩然天下
由于篇幅所限,其他前沿技术如持续学习、模型蒸馏等就不再赘述,仅做概括如下:
持续学习(Continual Learning):引入弹性权重巩固(EWC)和参数隔离技术,保护旧任务关键参数不被覆盖,结合增量学习实现知识累积。部分研究通过“记忆回放”模拟历史数据。
复杂任务分解:基于强化学习与图神经网络(GNN),将目标拆解为可执行的子任务序列,通过递归验证与反馈循环优化路径规划。
情感与意图识别:多模态融合架构,文本层使用BERT提取语义情感,语音层通过Wave2Vec提取声学特征,联合训练分类器识别情绪强度与潜在意图。
模型蒸馏技术:通过“师生学习”框架,将大模型输出概率(软标签)作为监督信号,训练轻量化模型模仿其行为,保留核心能力。
七、本篇小结
在人工智能发展的历史性跨越中,基于Transformer架构的大模型仅用短短四年时间,便完成了从实验室突破到万亿级市场规模的华丽蜕变。这一跨越不仅凝聚了全球顶尖人才的智慧结晶,更开创性地融合了数学、统计学、物理学、生物学、社会工程学、人因工程学以及经济学等多元学科的交叉创新。
本文系统性地构建了对大模型的认知框架:从基本概念界定出发,深入剖析了大模型算法的基础需求、演进路径与核心原理,初步探讨了智能涌现的情况,并前瞻性地展望了前沿技术发展方向,较为完整呈现了大模型底层软件的技术全貌。在接下来的篇章中,我们将从大模型硬件新基建领域出发,深入解析全球市场竞争格局,特别是聚焦中美两国在这一战略领域的博弈态势与发展前景。
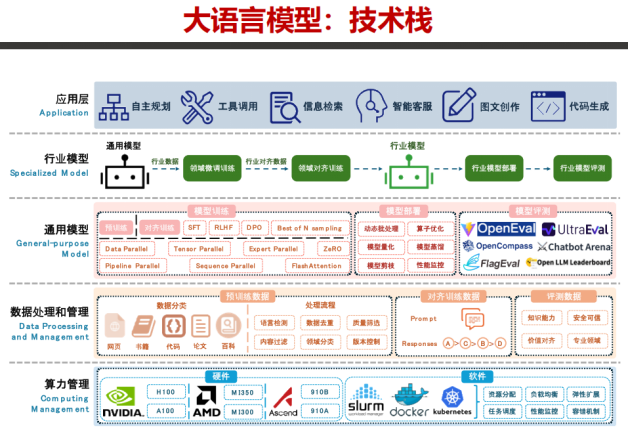
图片截取自天津大学《深度解读DeepSeek:原理与效应》